What began 2025 as bold experiments became the industry standard by year’s end. Two paradigms drove this shift: reasoning models (spending tokens to think before answering) and agentic tool use (executing code to interact with the world).
This subjective review of LLMs for software engineering covers three stages: the experimental breakthroughs of the first half of 2025, the production struggles where agents were often too chaotic to be useful, and the current state of practical, everyday tools.
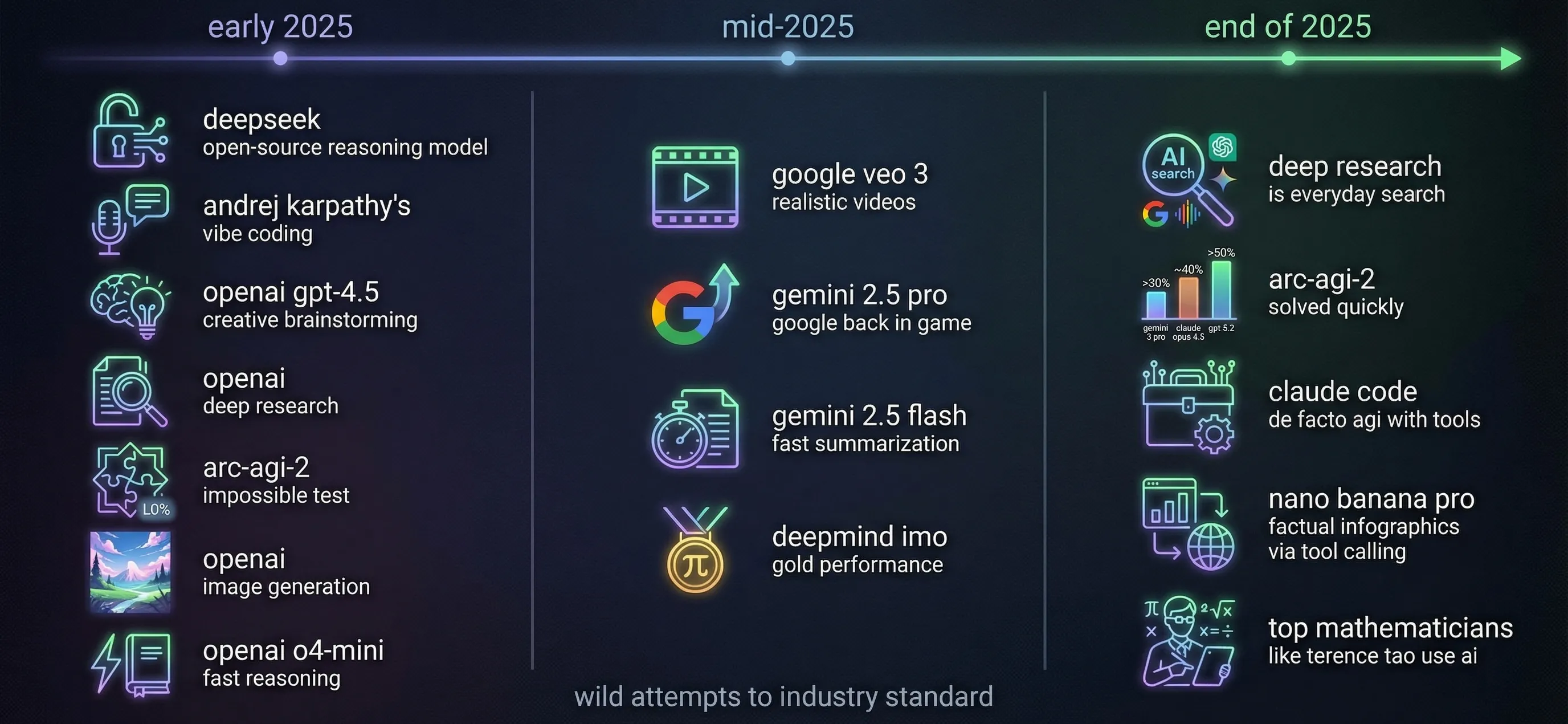
Visual summary of the three stages of AI in 2025 - generated from initial draft, with Nano Banana Pro.
First half of 2025
January
- DeepSeek released the first open-source reasoning model, DeepSeek-R1, sharing both weights and know-how. It broke the paradigm that AI is, and will remain, an oligopoly of proprietary models. Previously we only had o1, released in Sept 2024 by OpenAI.
February
- Andrej Karpathy coined the term “vibe coding” for programming where we primarily use plain language rather than code. For me, it took time to sink in. Now, it is a thing I do for hours a day.
- Later, OpenAI released GPT-4.5 - a real marvel. While it got closed and nothing matches its ability to brainstorm - more frank, less reserved and censored, creative, adjustable - I miss it, or should I say, them. It was expensive (
$2per single run in Cursor), but unparalleled at advanced translations. - OpenAI released Deep Research, which spends time doing multiple searches and summarizing them. Initially costly and slow, but still saving time on web search.
- Anthropic released command line tool for agentic coding Claude Code as research preview.
March
- ARC-AGI-2 was an attempt to create a test for AI that is impossible to solve. Top models had 1% or so performance.
- OpenAI released its 4o Image Generation model, flooding the web with Studio Ghibli pastiches.
April
- OpenAI released o4-mini, a smart yet reasonably fast reasoning model. In a brief conversation, it explained Einstein’s General Theory of Relativity to me - a topic I had struggled to understand despite many approaches.
May
- Google released Veo 3, allowing us to create videos that are sometimes hard to distinguish from real recordings.
June
- Gemini 2.5 Pro brought Google back to the AI game. And with Gemini 2.5 Flash, we finally had a model good at summarization and data extraction, yet fast and cheap.
July
- DeepMind achieved gold-level performance at the International Mathematical Olympiad.
From worldwide achievement to everyday production
And that was just the first half of 2025.
Progress arrived with significant caveats. We saw impressive demos and breakthroughs that often failed in production:
- Too slow or costly: Early reasoning models (o1) and web search AI agents (Deep Research) were powerful but impractical for daily loops.
- Overcaffeinated AI agents: Tools like early Claude Code (with Sonnet 3.7) were as likely to wreak havoc on your codebase as to fix it.
- The uncanny valley: Image generators (initial 4o Image Generation and Nano Banana) created stunning visuals but were unreliable for complicated instructions or text rendering.
The potential was undeniable, but extracting it required heavy lifting: extensive prompt engineering beforehand and rigorous auditing afterwards. It felt like managing an intern who needs constant supervision rather than collaborating with a capable colleague.
For pragmatists who ignore benchmarks and hype, the calculation is simple: does the tool improve net efficiency? A model that performs a task—a technical feat in itself—is useless if it demands more time in manual cleanup than it saves.
Now
A lot of things that were research achievements by the first half 2025, by its end became tools used daily.
Reasoning is mainstream
The first reasoning model was OpenAI o1, released Dec 2024. Likely thanks to DeepSeek-R1, other labs could move forward, making it both smarter and faster. Now all main models do that, especially the leading ones - GPT 5.2, Opus 4.5 and Gemini 3 Pro.
Deep research
Now, what was costly with Deep Research is an everyday search with any major AI provider - ChatGPT or Google Gemini. The peak performance of reasoning models from early 2025 is now way faster, cheaper, and more accurate. It is no longer a separate operation, but searching is a tool, that can be done iteratively, and combined with other actions. It changes from AI that hallucinate a lot to ones that can web search and fact-check themselves.
Open source is back into the game
Dec 2024, there was release of DeepSeek model, first open source model in the league of proprietary. Now, there are more. Various iterations of DeepSeek, Kimi-K2 Thinking, MiniMax-M1, GLM-4.7, and Mistral 3. Even hell froze as OpenAI released open source models.
AGI benchmarks
ARC-AGI-2 and Humanity’s Last Exam were tests created to be purposefully hard, to last longer than typical benchmarks.
Yet, by the end of 2025, for HLE Gemini 3 Pro has 37%. For ARC-AGI-2, Gemini 3 Pro solves over 30%, Claude Opus 4.5 almost 40%, and GPT-5.2 over 50%. It was not a test meant to be beaten so quickly!
Agentic coding
Claude Code is de facto AGI. Not necessarily superhuman yet, but capable of doing anything. If you can operate with code, and calling external APIs, you can do anything. It took me some time to pick that, as I favoured semi-manual use of Cursor. Yet, with multiple mentions on Hacker News I gave it a go and it permanently became one of the things in my toolbox. It’s development was nicely described in How Claude Code is built by Gergely Orosz, the Pragmatic Engineer.
With Claude Sonnet 3.7 it was awkward. With great power comes great responsibility - and this model often wreaked havoc on the codebase while not solving the main issue. Yet with better and better models it became both faster and smarter: Sonnet 4 was better, then Opus 4 better but slower (and expensive), Sonnet 4.5 same power but way faster, and Opus 4.5 - same speed, but smarter.
All you need is a sufficiently strong model, long context, and the ability to call tools to get everything done. They can search, gather information, extract, and visualize whatever you need. With Opus 4.5, we get a lot of power at a fast pace.
Other players followed - there is Codex CLI by OpenAI, Gemini CLI, and Cursor CLI. See more on testing agents and models in Migrating CompileBench to Harbor: standardizing AI agent evals.
Image generation
Nano Banana Pro changed the game, from images for concept art to one able to generate infographics and charts - factually correct, based on web searches. You can easily add to your agentic workflow - using Antigravity or Claude Skills.
Advanced uses
It is no longer a tool to do maths homework or for research challenges like international olympiads. It is becoming a tool for working.
Quantum computing researcher Scott Aaronson and Field’s Medalist Terence Tao use AI to advance their studies.
Sure, it still makes silly mistakes. But in smart hands, it gets even smarter.
Conclusion
It was the most intense year when it comes to AI development. One crucial part is that many things that were great tech demos but not usable in everyday work, are now standard tools.
I just scratched the surface of selected model releases (even not all I used), not even all demos I got mesmerized by or research papers. I recommend insights 2025 LLM Year in Review by Andrej Karpathy (also referring to his “vibe coding”), a nice overview 2025: The year in LLMs by Simon Willison and AI News, a daily newsletter I have been following the whole year.
Even if my job is fully focused on AI, and in free time I am also excited by it as well, it is impossible to keep track.
Stay tuned for future posts and releases