Compare harnesses not models: Blitzy vs GPT-5.4 on SWE-Bench Pro
Last year, agentic IDE tooling and vibe coding went mainstream. But enterprise systems – payments, mainframes, decade-old technology – aren’t disrupted by this. These codebases are enormous, require massive context, have very little public training data for the models to learn on, and are mission critical to the business. There is a massive untapped market here.
For enterprise codebases, the model alone is not enough, placing a massive emphasis on the agent harness or orchestration layer. In particular, Blitzy, an agentic software development platform, recently achieved a 66.5% score on SWE-Bench Pro Public, one of the leading AI coding benchmarks. The current state-of-the-art base model on this benchmark is GPT-5.4 (released early March 2026), which achieved a score of 57.7%.
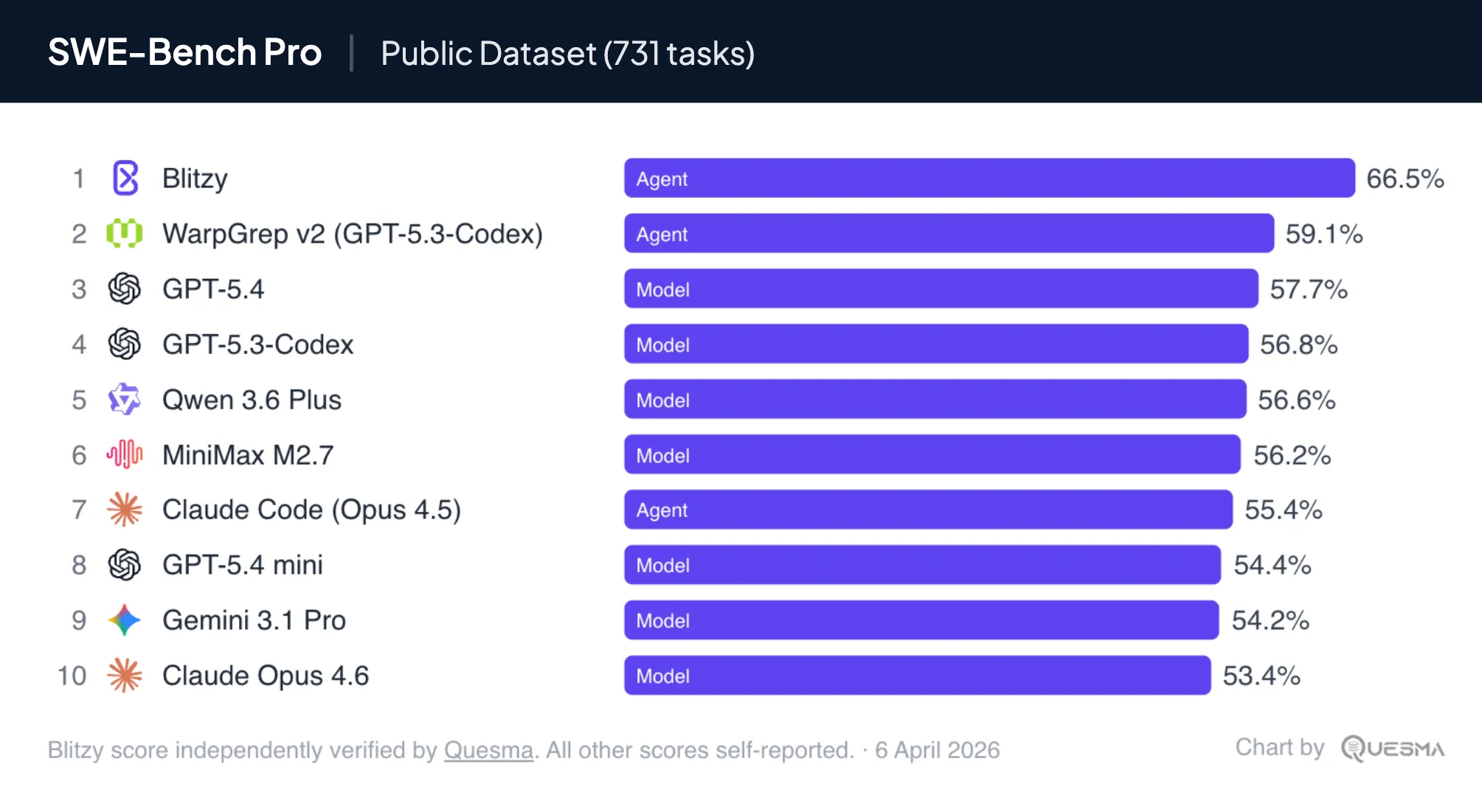
All SWE-Bench Pro Public scores are self-reported. Blitzy’s score was independently verified by Quesma. Top results: Blitzy (66.5%), WarpGrep v2 (59.1%), and GPT-5.4 (57.7%).
SWE-Bench Pro Public is run by Scale AI, a company that primarily sells data to model owners. They have no incentive to validate harnesses, only base models.
Yet, with base models already being smart enough to tackle hard PhD-level questions, the missing gap is how to utilize infrastructure around the models to drive better and more consistent performance. Recent tests on a planning benchmark showed that a harness offered an improvement for Gemini 3.1 Pro, Claude Opus 4.6 and GPT 5.4 over their native Gemini CLI, Claude Opus, or Codex.

For example, a fragment of the Gemini 3.1 Pro announcement shows GPT-5.3-Codex achieving a much higher score on Terminal-Bench 2.0 with its dedicated Codex AI agent than with the benchmark-default Terminus-2.
That’s the gap Quesma fills: we stepped in to independently verify whether a harness can genuinely outperform raw models in these complex environments, and what the actual advantage is.
We were contracted by Blitzy to audit and verify their results. Our goal was to ensure their process adhered to benchmarking best practices. We audited their execution environment and required them to apply our recommendations before validating the run. Here is what we found, and what it implies for enterprise software development.
How enterprise harnesses differ from standard IDE agents
Blitzy describes itself as an autonomous software development platform purpose built for complex, large enterprise codebases. Its interface differs significantly from the terminal tools (like Claude Code) or IDE integrations (like Cursor) most engineers are used to. Instead of targeting solo developers, it focuses on enterprise workflows – and it mirrors a seasoned enterprise engineering team’s process.
Before Blitzy starts any work on code generation, the platform launches collaborative agents to deeply analyze the repository – mapping dependencies, understanding conventions, and capturing domain logic. This documentation process can take hours or days. When prompted to add a feature, refactor code or fix bugs, Blitzy replies with a highly detailed technical specification. Once confirmed, the platform sequences the work, spawns specialized agents and coordinates them to execute the plan and validate the code before shipping.
Blitzy is an opinionated platform that spends vast amounts of time (and tokens) deeply understanding a codebase. It takes considerable effort to draft a precise execution plan – very much in the spirit of spec-driven development – and it explicitly verifies its results before showing code to engineering teams, rather than cutting corners. Its pricing is accordingly at the enterprise level, rather than the $200/month most of us are used to.
Auditing the 66.5% SWE-Bench Pro score
SWE-Bench Pro is one of the key industry benchmarks for AI coding capabilities, typically listed alongside Terminal-Bench 2.0 during new model releases. Its tasks, rather than artificially created puzzles, are real-world GitHub issues extracted from open-source repositories. SWE-Bench Pro serves as the successor to SWE-bench Verified, which not only saturated at around 80% but also may not distinguish newest models. For reference, Blitzy scored 86.8% on SWE-Bench Verified; just as this benchmark is getting discontinued, its public leaderboard does not accept closed-source agents’ scores.
Verification - was there any reward hacking?
Agents are smart and resourceful. They can find loopholes, investigate available tools, search online for solutions, and notice if there are some extra resources they can use to extract hints. In the real world, we want to use every piece of knowledge. In benchmarking it is different - we need to restrict resources, so that results can be compared fairly.
Blitzy sent us both solutions and trajectories - long files with tens to hundreds of interactions between agents and their system (called agent turns). We re-ran the solutions and checked for things that are likely to affect the result - any web searches, internet access beyond installation procedures, access to unauthorized git branches, or any other indicator of a leak like referencing previous runs or GitHub issue numbers. It would be a red flag if the suggested code change is too close to a reference solution (so-called golden patch).
We found nothing that would affect the score. All irregularities were benign or within the quirks of the benchmark itself. Score holds!
Why raw models fail at the last mile
We wanted to understand why Blitzy succeeded where the best raw model fails. As trajectories for GPT-5.4 are not available, we ran it on the most difficult tasks solved by Blitzy.
While in some cases GPT-5.4 failed, in the majority of cases the incorrect solutions were “almost there”. The model generally had a good idea of the fix, but got lost in the execution details.

A sample of 9 tasks solved by Blitzy, but not by GPT-5.4, with reasoning setting set to xhigh.
Verdict for Blitzy
With the benchmark score verified and the raw model’s shortcomings clear, the takeaway is straightforward. What we have seen is the difference in the last step of making sure the code actually works.
Terminal-based coding agents often operate with a “fingers crossed” mentality. They eagerly commit and push, but when asked if they actually ran the tests, the models admit they haven’t – but insist the code “should work”. That is the fundamental difference between an enthusiastic intern and a senior software developer.
It is highly likely that Blitzy’s performance edge is even more pronounced in closed-source enterprise projects, especially those relying on rare technologies or internal frameworks. In those environments, having agents that methodically document the repository and rigorously verify its changes makes a night-and-day difference.
The fundamental tradeoff between time, quality, and money
Software development is always a tradeoff between time, quality, and money. For fast-paced startups, speed is the primary factor and developers are encouraged to “move fast and break things”. Claude Code was built for this workflow.
For a vibe coder, waiting a few hours feels like ages. But for a real-world enterprise scale project, it represents incredibly fast-paced development – especially when you need well-specified features, intricate refactoring or reliable bug fixes for a mature codebase, rather than just spinning up a small, greenfield project.
Mature, enterprise projects require a much more methodical approach. In mission-critical systems (like payment infrastructure or legacy mainframes that still process the majority of global credit card transactions), the same “move fast and break things” mentality is a liability.
Burning more tokens does not guarantee better results. Designing delightful frontends with GPT-5.4, an official tutorial by OpenAI, recommends:
For simpler websites, more reasoning is not always better. In practice, low and medium reasoning levels often lead to stronger front-end results, helping the model stay fast, focused, and less prone to overthinking, while still leaving headroom to turn reasoning up for more ambitious designs.
The future of AI coding is in the scaffolding
For end customers, harness vs. model is irrelevant – what matters is the result. And we’re seeing (e.g. with our Blitzy vs. GPT-5.4 comparison) that harnesses matter more this year than just switching between frontier models. While base models are constantly evolving, the most impactful change might actually be the evolution of the agentic harnesses built around them. It is worth remembering that Claude Code is still less than a year old!
Until recently, AI agents were primarily geared toward solo developers building greenfield applications or tinkering with side projects. But since December 2025, base models have become vastly more powerful, and the major releases in early 2026 have only doubled down on that trend. The race to build AI tools for solo developers is already well underway, but the race for autonomous, enterprise-grade engineering agents has only just begun.
Stay tuned for future posts and releases