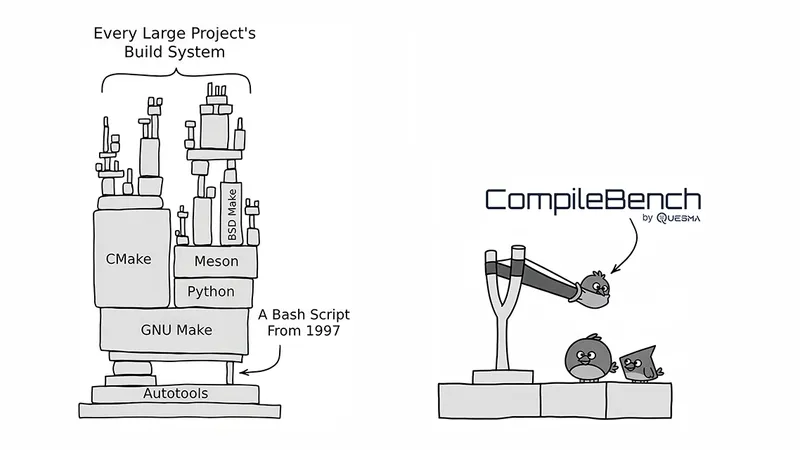
Migrating CompileBench to Harbor: standardizing AI agent evals
When we released CompileBench, our benchmark for testing if AI agents can compile open-source projects, it hit the front page of Hacker News.
Behind the scenes, our task runner and execution harness (a mix of Go, Rust, Python, and shell scripts) were becoming a ball and chain. We realized that to keep up with the pace of AI, we needed more than just a set of scripts. We needed a standardized framework to solve the hard problems of agent evaluation.
That’s why we migrated to Harbor. It’s a new, open source framework for evaluating and optimizing agents and models in container environments, developed by Laude Institute, the creators of Terminal-Bench. We were motivated by:
- Maintenance: Both tasks and the execution harness need maintenance, while we wanted to focus on the actual tasks.
- Reproducibility: It’s core to science and pragmatic for engineering.
- Agility: Switching execution environment from local Docker to cloud-based, easily running against new models, or using the setup for fine-tuning.
- Collaboration: With a common format, it is easy to work with other teams and contribute to other benchmarks.
- Extensibility: In case we hit a limitation, we shouldn’t be required to fork the project but rather extend it or contribute directly.

Laude Institute created Terminal-Bench 2.0, one of the key benchmarks for measuring agentic software development. It is mentioned in the release of Claude Opus 4.5 and of GPT-5.2-Codex. Needless to say, it runs in Harbor.
The light of Harbor
We got excited when the same post announced the release of both Terminal-Bench 2.0 and Harbor.
We had to try it ourselves. Harbor is a Python-based tool, easily installed with uv:
uv tool install harborRunning tasks is as simple as:
export OPENROUTER_API_KEY=...
harbor run \
--path "my_tasks/build-coreutils-old-version" \
--agent "terminus-2" \
--model "openrouter/google/gemini-3-pro-preview"By default, tasks run locally in a Docker container. However, there’s built-in support for SaaS execution environments such as Daytona (just use --env daytona) or E2B.
You can pick your fighter LLM agent. Options include the default Terminus-2 (used in TerminalBench), headless modes of popular CLI tools like Claude Code, OpenAI Codex, and Cursor CLI, or you can create your own agent.
To communicate with models, Harbor uses LiteLLM, making it easy to switch between both models and providers. Note that while Terminus-2 can use any model, not all combinations are possible. You cannot use, say, the Gemini 3 Pro model with the Claude Code agent - unless as an AI skill.
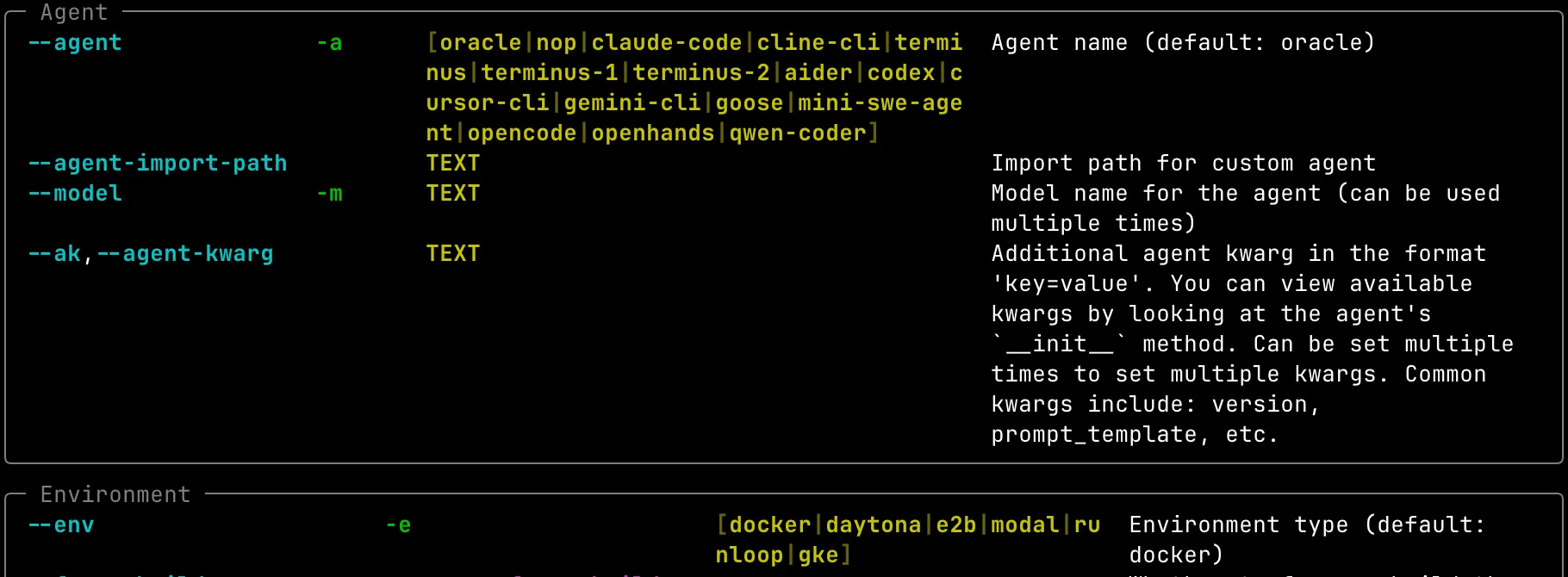
Just type harbor run --help. Overall, we like the developer experience, including the getting
started.
You can also create your own agent if you want to benchmark agents themselves, rather than tasks or models.
A task itself is just a simple collection of files within a single directory, following this convention:
├── task.toml # metadata (author, labels, etc)
├── instruction.md # prompt passed to the agent
├── environment # environment, input files
│ ├── Dockerfile
│ └── ...
├── solution # optional reference solution
│ ├── solve.sh
│ └── ...
└── tests # task grading logic
├── test.sh # any script that saves score
└── ... # e.g. pytest fileExamples use scoring output with pytest. But you can use any framework, in any language, as long as it saves score to /logs/verifier/reward.txt.
Docking at Harbor
After initial tests, we wanted to give it a serious try - migrating CompileBench. Migrations from a custom solution to a framework are risky. Often they require much more rewriting than expected, have rough edges, or hit a dead-end when a framework does not support a required feature.
Luckily, Harbor hit the sweet spot. Migration went surprisingly smoothly. The general feel was that we could create tasks as we wished, just sticking to its (very sensible) convention. Harbor provides what’s needed and offers an easy way to extend its capabilities.
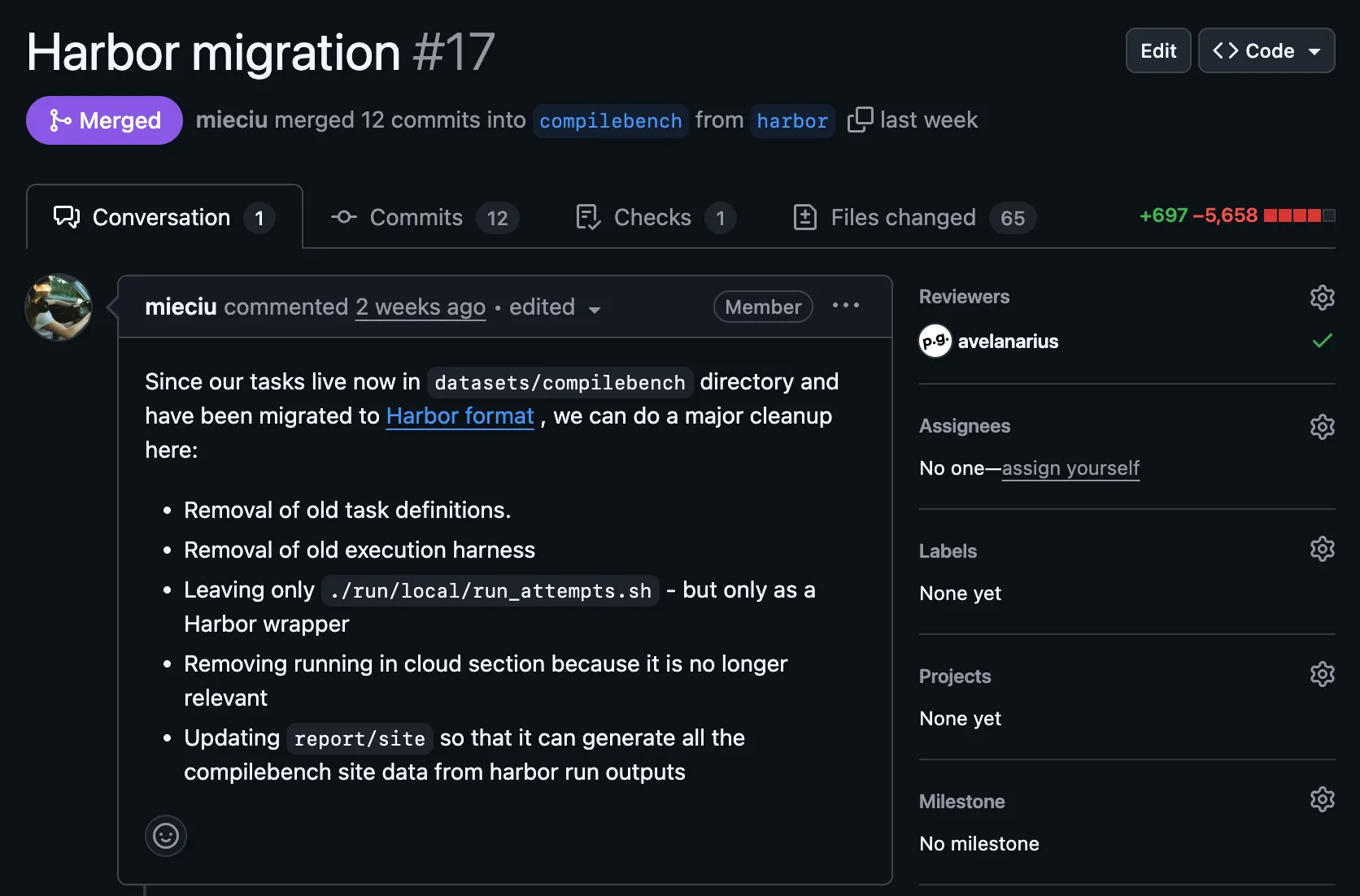
Massive reduction in lines of code - see migration and cleanup. When we created our impromptu framework for CompileBench, we weren’t lost at sea. But Harbor put wind in our sails!
And the benefits were immediate:
- Beautiful codebase cleanup - there is no better testament than the massive reduction in lines of code shown in the PR.
- Nicely separated tasks - each benchmark is now its own self-contained unit, easier to manage and update.
- Maintenance-free harness - we now have a robust, working execution engine that we don’t have to maintain ourselves, letting us focus on the evaluations.
Now that we are part of the official Harbor datasets registry, running CompileBench is as simple as:
harbor run \
--dataset [email protected] \
--task-name "c*" \
--agent terminus-2 \
--model openai/gpt-5.2It is now simpler for you to run CompileBench than it was for us before the migration!
Views from Harbor
We were already used to visualizing trajectories — the conversations between the AI agent and the system, including tool calls and their results.
In CompileBench we had our own visualizer (see 135 steps in the compilation of coreutils), which was crucial to see how the agent tackles a problem and where it fails.
Trajectories are invaluable for debugging tasks. They reveal if we missed providing a file or tool, or if the agent misunderstood the solution (e.g., building a binary in the wrong folder).
We came up with an idea for a simplistic web server that watches trajectory files and displays them live. The implementation was easy, as Harbor relies on the well-defined Agent Trajectory Interchange Format.
We opened a PR, and it turned out the maintainers were already thinking about this exact feature. Our contribution got folded into a larger effort, and as of today, it’s shipped! We loved chatting with the folks at Laude Institute over Discord.
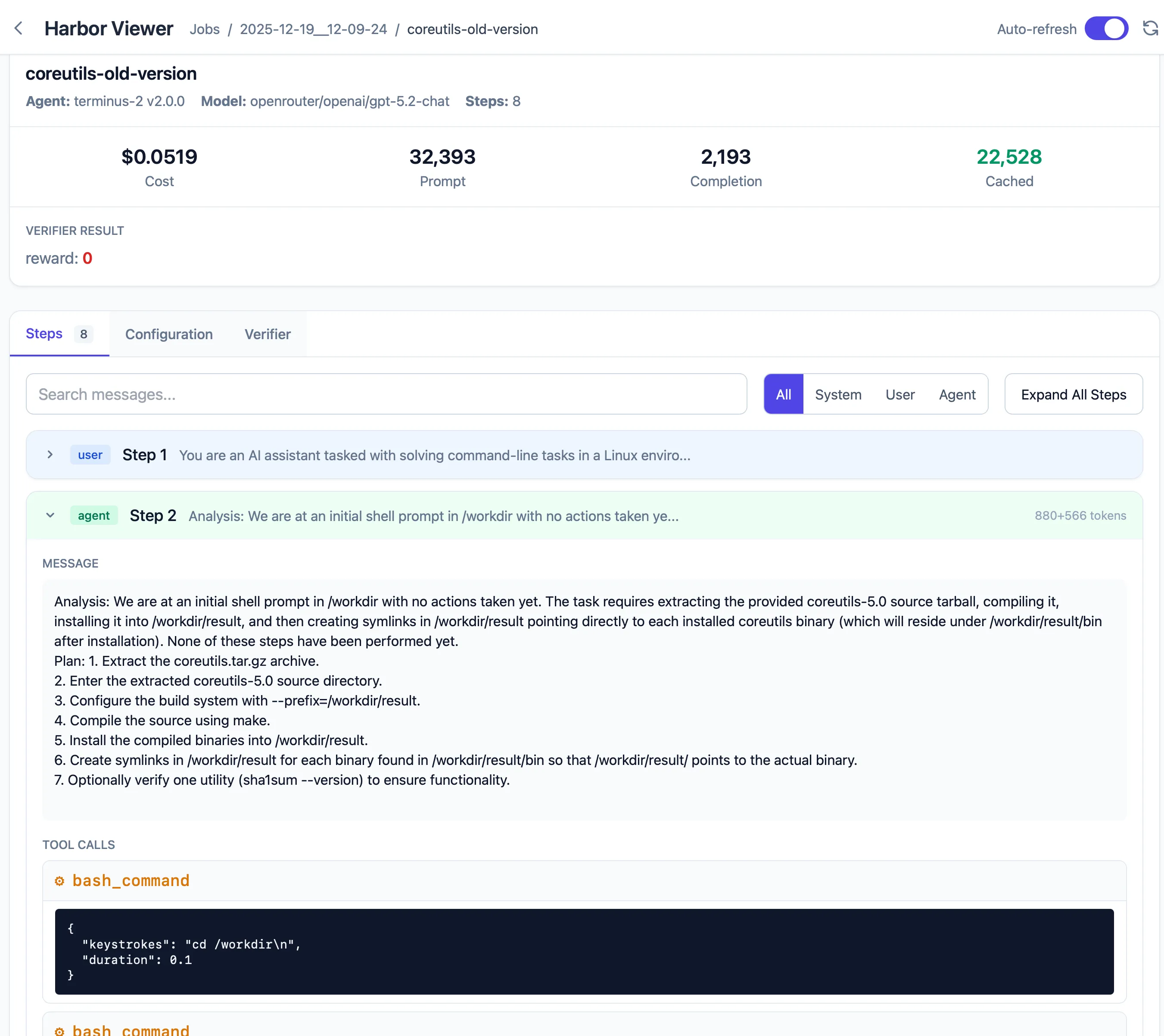
Harbor trajectory viewer, visualizing agent interactions in real-time.
Conclusion
Harbor makes it much easier to create evals and benchmarks for AI agents. It works out-of-the-box, and is reasonably easy to customize to your needs.
The landscape of evaluations, reinforcement learning and supervised fine-tuning is fragmented. Everyone is doing it their own way, more akin to tinkering than systematic engineering. We strongly believe that the industry needs more open-source tooling and shared standards. Harbor feels less like “yet another framework” and more like a foundational tool the community has been missing. Previously, each benchmark was different. Running them meant understanding inner logic, idiosyncrasies, opinionated choices, and getting the right API keys. With Harbor, we can literally run a dataset in one line.
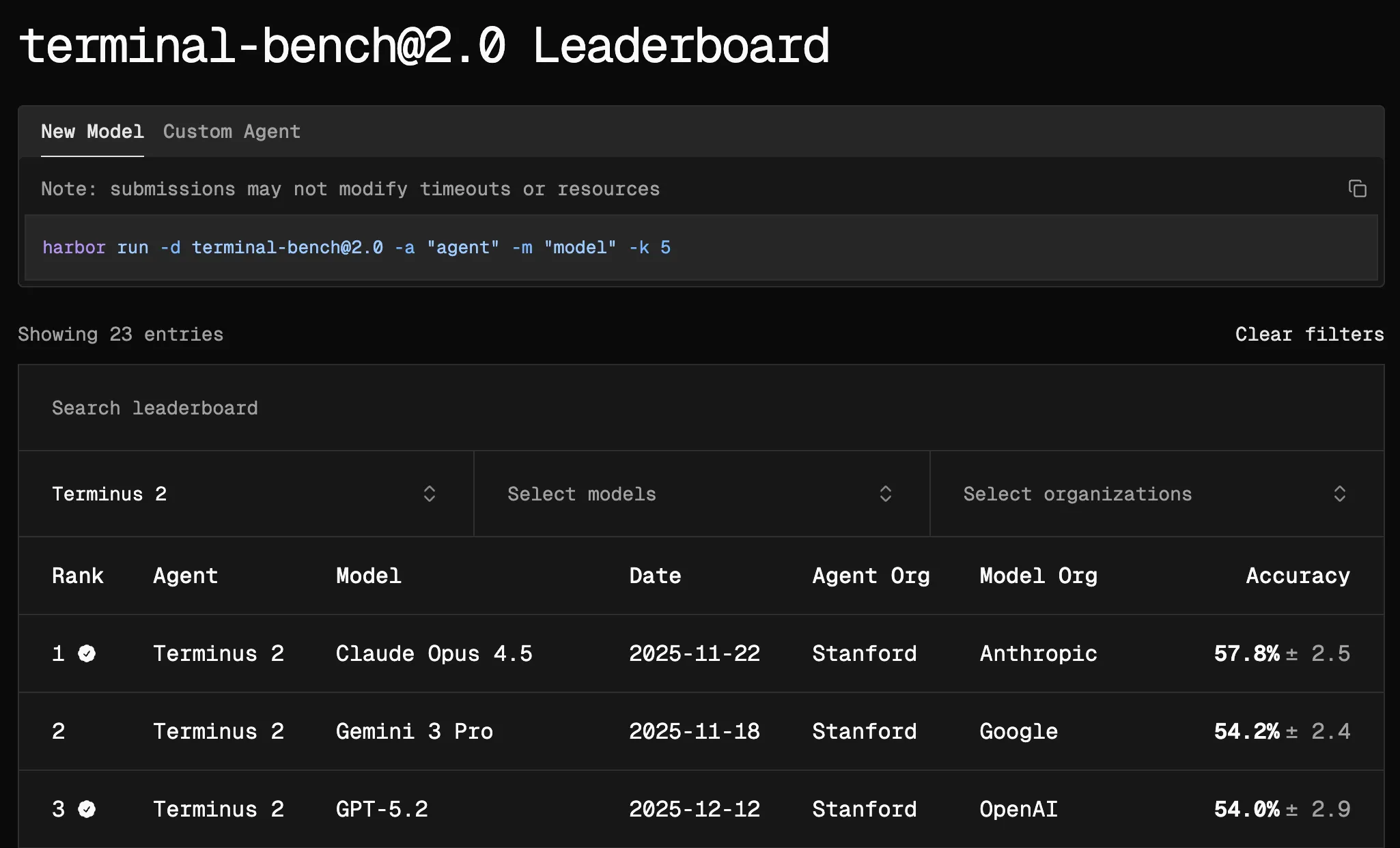
Terminal Bench 2.0 leaderboard showing Terminus-2 performance on various models.
Stay tuned for future posts and releases