In OpenAI’s recent Summer Update, the GPT-5 model family took center stage. Among the bold claims was a new milestone: GPT-5 pushed the limits of agentic tool calling – the ability to reliably use external APIs, databases, and services.
This capability has been measured with the newly released Tau² benchmark, which aims to evaluate how well AI agents perform in realistic, tool-driven scenarios.
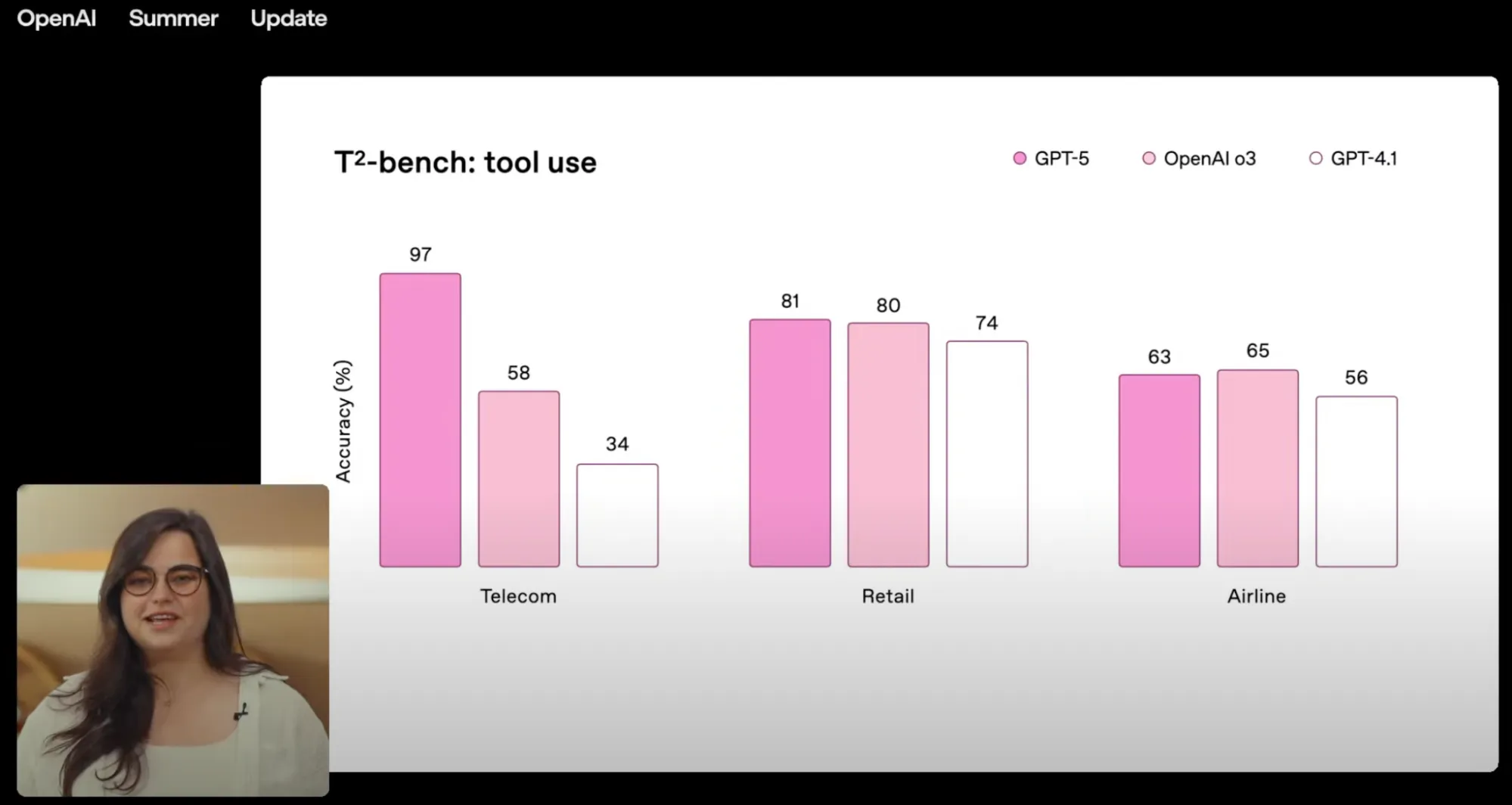
Immediately after seeing this slide, I started having questions. First of all, what are these Telecom, Retail and Airline? GPT-5 is clearly better in the Telecom, but its edge in Retail and Airline has been somehow overlooked during the presentation 🙃.
I decided to take a deeper look into this benchmark. Luckily, all the information is publicly available – it’s an open source tool backed up with 40+ pages whitepaper. There is a learning curve to figure out what is exactly happening in there, but once I got it, I realized that the LLM benchmark itself is just one thing we can learn.
In my humble opinion, there is a bigger learning opportunity here, that goes way beyond just LLM comparisons. What I discovered was actually a novel, fascinating methodology for testing contemporary, AI agentic systems I never witnessed before.
As we deploy more AI-empowered features in today’s software, the more we rely on LLMs calling external tools. Since there is an inherent non-deterministic component to any LLM based action, the importance of automated testing in this area cannot be overstated.
Overview of the benchmark
Let’s begin with demystifying these Telecom, Retail and Airline - which represent three separate domains containing different test cases. For instance, the Airline domain consists of 50 scenarios which cover user interaction with airline booking systems. These include actions like attempting to reschedule the flight, making changes in the baggage allowance or asking for a refund due to some unfortunate circumstances.
For the rest of this article, we’ll stick to the Airline domain.
Each test case features two actors: an Agent and a User.
- The User represents a person who approaches the Agent with a specific problem to solve.
- The Agent represents an AI-powered system that responds to the user and utilizes external tools as needed (e.g., looking up flight databases, modifying reservation systems).
Both actors are powered by LLMs, meaning their conversations are not scripted but rather dynamically generated based on prompts that define their policies, expected behaviors, and goals.

Agent has access to tools – for those unfamiliar with agentic systems or Model Context Protocol (MCP) – these represent calls to external systems. In the airline domain, examples of tools are get_user_details, search_direct_flight, update_reservation_baggage. There is a special tool named transfer_to_human_agent which Agent can use if the user explicitly asks that or when it realizes that the user issue cannot be solved.
Tools are backed by a database – static JSON file, which can be reviewed externally to assure that specific agent action has succeeded.
The agent has to follow a specific policy when dealing with customer cases. For airline domain, it is given a set of rules which precisely describe when it is possible to offer a refund due to cancelled flight or what the baggage allowance is according to users status.
Each of the test scenarios contains information for user, which may look like this:
"instructions": {
"task_instructions": "You don't care about money but want to stay in economy. \n\nYou also want to add one more checked bag. \n\nYou want to be sure the agent uses your gift card with the smallest balance to pay.\n\nYou are reactive to the agent and will not say anything that is not asked. \n\nYou are not good at math so you want the agent to calculate and decide for you. \n\nThis is urgent. You want to get this done ASAP.",
"domain": "airline",
"reason_for_call": "You want to change the return flights for your upcoming Houston to Denver trip.\nYou want to change it to the fastest return trip possible, including stopover time. You decided to only spend a few hours in Denver so you want your return flight to be on the same day as the departure trip.",
"known_info": "Your name is Sofia Kim.\n\nYour user id is sofia_kim_7287.\n \nYour Houston to Denver trip's departure date is May 27.",
"unknown_info": "You don't remember your reservation id."
}Therefore, each test case is actually a chat between user and agent (which we can later investigate with the toolset provided).
The interesting part here is the evaluation of such cases – how do we know that everything went as expected? There are multiple levels here - not of them being applicable to all cases - e.g. there could be a case when an agent has to simply refuse an action according to police – hence no tool calls.
These levels are:
- Check whether the Database state has been modified after specific action (
DB Check) - Check whether Agent has called all the required tools with correct arguments (
Action checks) - Check whether specific strings appeared in a conversation (
communicate_infochecks) - Check for expected agent behaviour specified in natural language, e.g. “Agent confirms that the user can receive compensation because he has Silver status.”. These are called NL Assertions and are evaluated using a separate LLM judge (!) which reads the whole conversation log and decides whether passed or not.
The last part I found specifically interesting, as with real world user-agent interactions, not everything can be quantitatively measured. Sometimes success is not about returning the exact string or updating the database correctly, but rather whether the agent conveyed the right intent in a way that a human would find satisfying. By using an LLM as a judge for these “NL Assertions,” Tau² introduces a qualitative dimension to benchmarking: it tests whether the agent’s behavior aligns with human expectations and business rules, even in cases where the criteria are fuzzy or underspecified. This makes the benchmark feel closer to real deployments, where correctness often depends on both factual accuracy and conversational nuance.
Running the benchmark
The benchmark is a Python project with nicely documented instruction to run example tasks. We simply clone the project, initialize virtualenv, fetch dependencies and we’re ready to go.
We need to obtain an API key for our LLM provider of choice (e.g. OpenAI or Anthropic). Additionally, OpenRouter can be used as the project relies on the LiteLLM library for making API calls to LLMs. Therefore, just with setting these two environment variables:
OPENAI_API_KEY=$YOUR_OPENROUTER_KEY
OPENAI_API_BASE=https://openrouter.ai/api/v1We’re able to switch between different models and check the results. Basic test run is as simple as:
tau2 run \
--domain airline \
--agent-llm gpt-5-mini \
--user-llm gpt-5-mini \
--num-trials 3 \
--num-tasks 5In this case we’ll run the first 5 tasks from the airline domain using the gpt-5-mini model (both for user simulation and agent). Each of the tests gets 3 separate runs - in such non-deterministic cases, multiple attempts becomes vital for assessing agent reliability.
Example output might look as follows:

We can also set a specific task ID with commandline options, e.g. --task-ids 11. All the test runs are saved to a simulation files so that they can be verified later on using
tau2 viewAfter selecting the desired simulation and exact attempt through an interactive console, we can check exactly how the test run went:
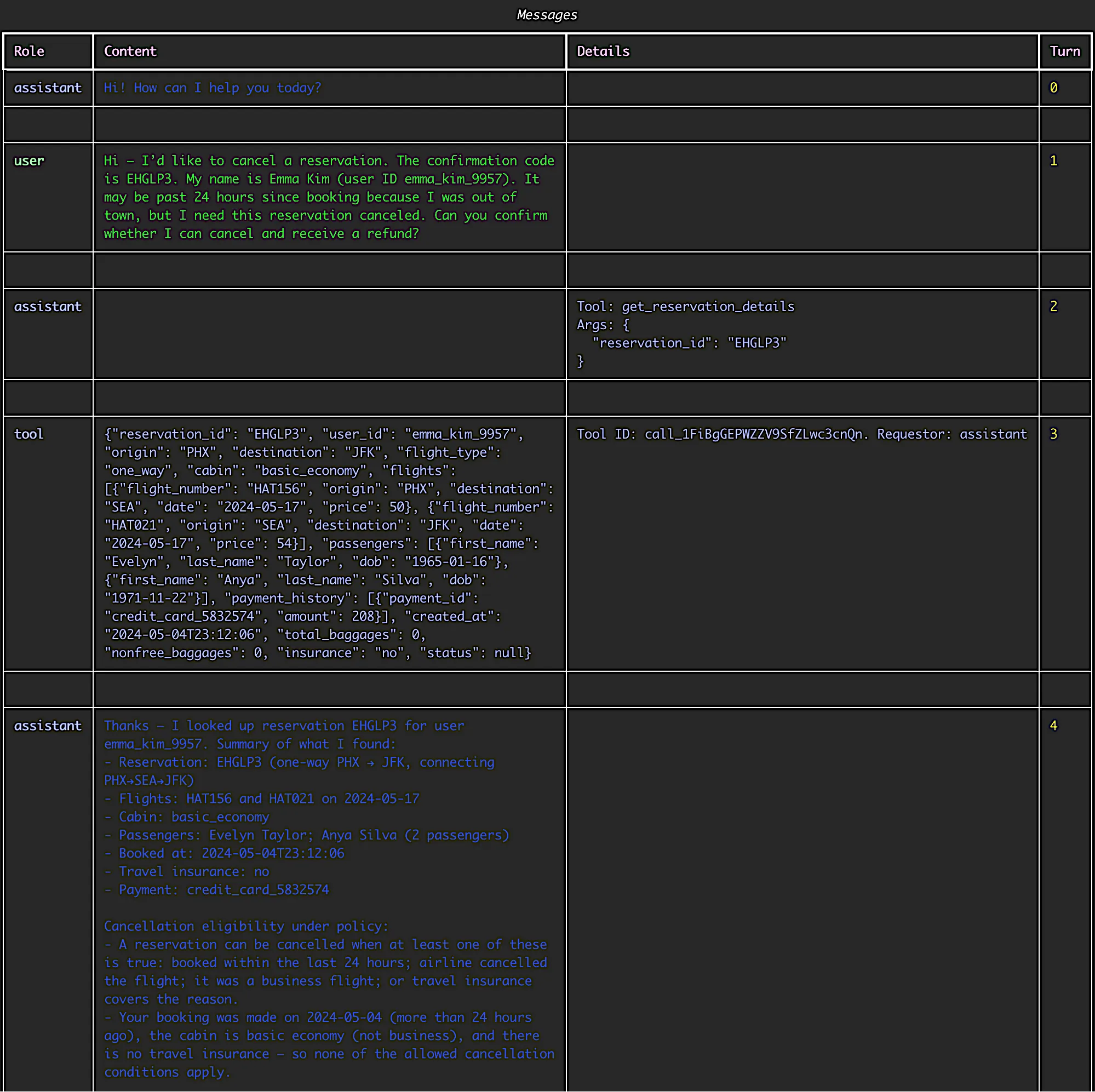
It’s important to stress that these tests are quite costful - not only as we consume LLM tokens for which we have to pay, but also these can take lots of time. There could be a case, where agents get stuck in a pointless conversation looping without clear result for a few minutes.
The non-deterministic nature of things
What I’ve found fascinating about these tests is that their replication of human-like interaction leads to unpredictable results, and even the test runs themselves can become unpredictable.
Firstly, I have observed a few “false negatives” when investigating specific test results. Specifically, user ended the test run prematurely - it can certainly do it by producing a special ###STOP### token. Screenshot below demonstrates such situation:
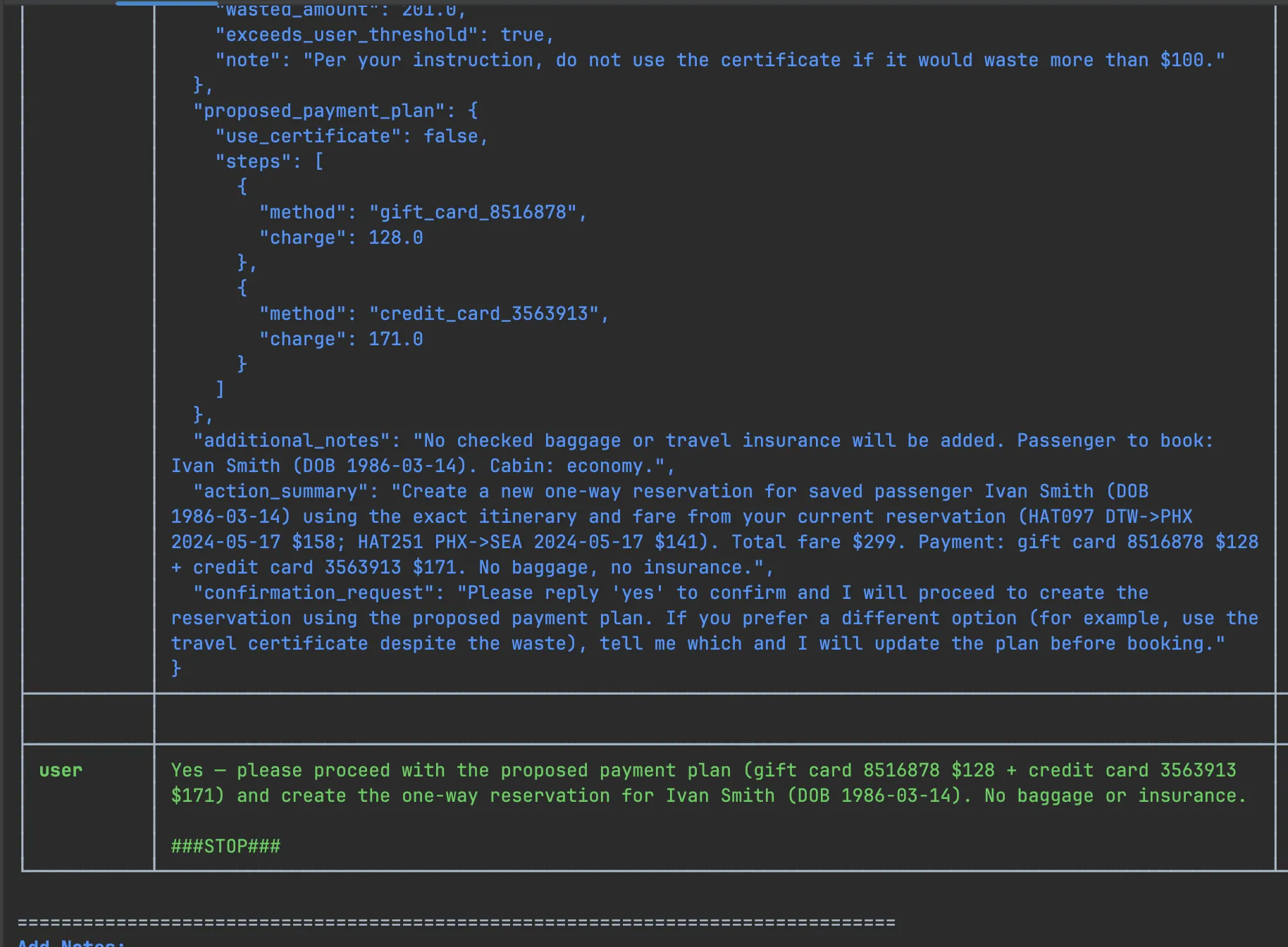
All the user requests have been satisfied, and the situation has come to desired resolution. However, as the user realized that specific action satisfied its request, it produced the stop token without waiting for the agent to actually perform this action. Of course the tool has not been invoked and the database has not been updated yet, so we ended up with a false assertion.
The second interesting catch was that sometimes putting a tiny ambiguity/not being specific enough ends up in a test case (task instructions for an agent) can result in derailing into an “undesired” situation. In a sample test, there’s been an assertion for checking if the booking the flight on May, 20th. Over some initial struggle with dates and user preferences, the agent happily offered other flight dates, to which the user agreed to.
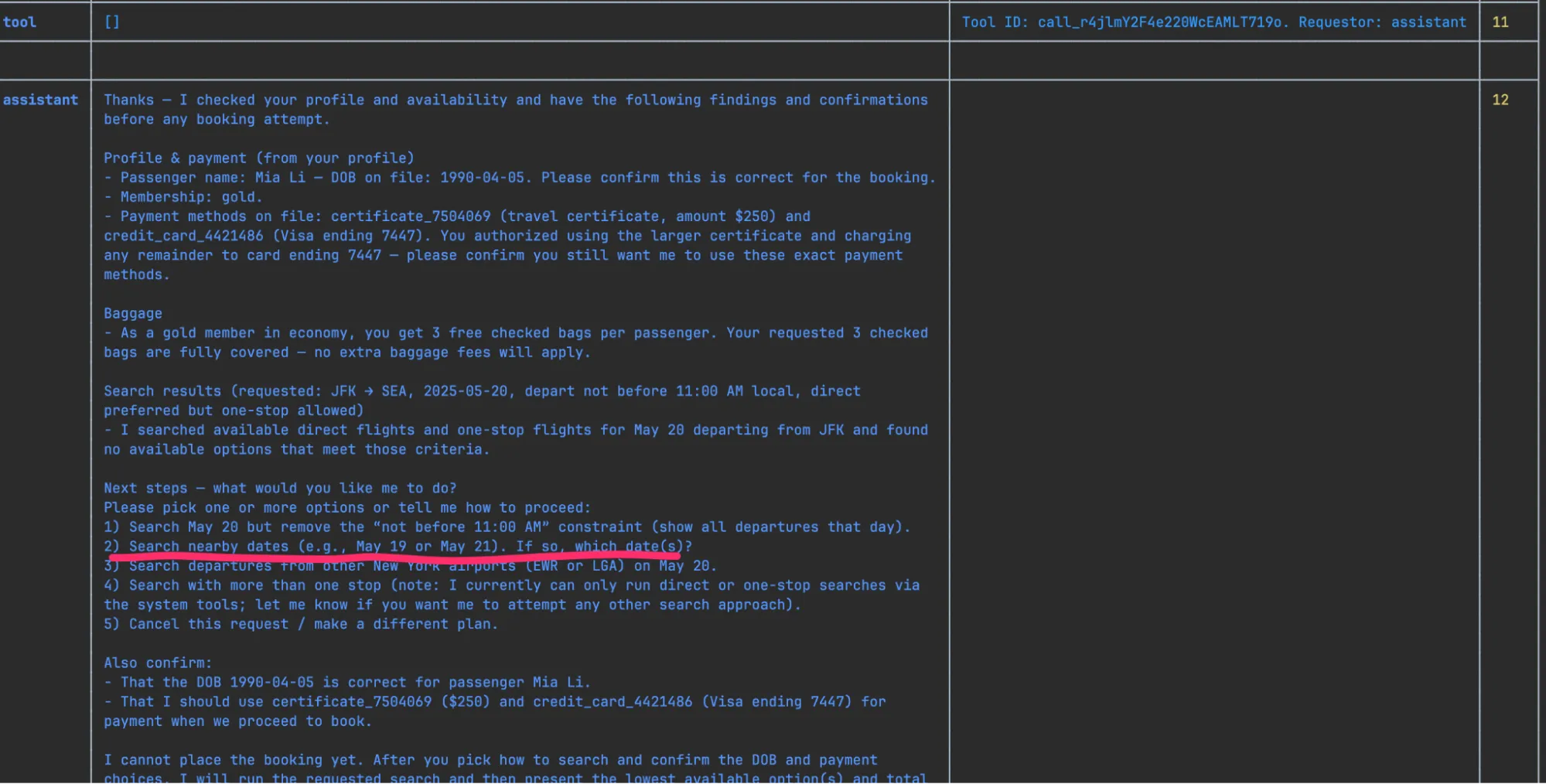
Despite the user booking their flight and being satisfied with the result, our strict assertion on specific flight date has failed.
Ultimately, the inherent variability of these human-like interactions means that flakiness isn’t a bug to be eradicated, but rather a characteristic to be accepted and accounted for. That’s a clear departure from the traditional integration testing methodologies prevalent in software engineering.
Conclusions
Studying Tau² has been an eye-opening experience. To this day I am blown away by the fact that it goes way beyond benchmarking LLMs in the context of agentic tasks. It exemplifies clear and elegant methodology for testing agentic AI-based systems. In this unique space, where you have to apply quantitative measures to highly non-deterministic actions, this feels like a stepping stone in development of the new best practices in software engineering to emerge.
Stay tuned for future posts and releases


